Slimme opsporing met QUIN - VVSOR - VVSOR
Netherlands Society for Statistics and Operations Research | Dutch
‘I have a certain friend – his name is Mr. Quin, and he can best be described in terms of catalysis. His presence is a sign that things are going to happen, because when he is there strange revelations come to light, discoveries are made.’ Agatha Christie – The Mysterious Mr Quin
Voortvluchtigen doen alle moeite om uit handen van opsporingsteams te blijven. Echter, ze laten toch vaak kleine sporen achter; een pintransactie, een telefoontje met een bekende. Dit is de context van het AvroTrosprogramma Hunted. Hierin moeten deelnemers zich gedurende drie weken schuilhouden en uit handen zien te blijven van een team dat werkt volgens de principes van opsporingsonderzoeken bij de politie.
Tijdens opsporingsonderzoek is de hoeveelheid informatie vaak zowel enorm beperkt als overweldigend. Van de zaak zelf is maar weinig bekend. In deze tijd van sociale media en mobiele telefonie zijn er tegelijkertijd enorm veel data beschikbaar over de persoon in kwestie. Denk aan sociale netwerken, alle Facebook-vrienden. Mogelijk geeft één van hen hem onderdak. Maar hoe haal je uit al die mogelijkheden datgene wat er echt speelt?
Dit jaar krijgen de rechercheurs in de serie Hunted hulp van zo’n Mr. Quin. QUIN (QUestion and INvestigate, tevens geïnspireerd op het personage Mr. Quin van Agatha Christie) is namelijk een methode en ondersteuningstool voor analisten en rechercheurs die beoogt richting te geven binnen opsporingsonderzoeken (Smit, 2016). Het uitgangspunt is: een zaak lijkt altijd op iets dat al een keer eerder is gebeurd. QUIN maakt gebruik van historische zaken, en gaat na welke het meest lijken op de huidige. In dit geval gaat het om de gedragingen van kandidaten uit eerdere series uit binnen- en buitenland. Die informatie wordt omgezet naar de huidige zaak: welk gedragspatroon past er bij het huidige bewijs? Welke scenario lijkt het meest passend? Deze informatie kan de rechercheur gebruiken om het onderzoek te sturen.
QUIN is een voorbeeld van hoe kwantitatieve analyses op historische data kunnen bijdragen aan opsporing en inlichtingen. Aan de basis van de aanpak van QUIN ligt een bekende criminologische aanpak genaamd crime scripting (Cornish, 1994), waarin crimineel gedrag wordt vastgelegd in scenario’s. Een script of scenario deelt een criminele activiteit op in scenes. Binnen die scenes zijn er actoren die handelingen verrichten, waarbij ze gebruik maken van bepaalde middelen, et cetera. Het gedrag van daders, criminele organisaties of deelnemers aan Hunted kan in een dergelijk format beschreven worden. Vervolgens kunnen de scripts geanalyseerd worden om gedragspatronen te herkennen.
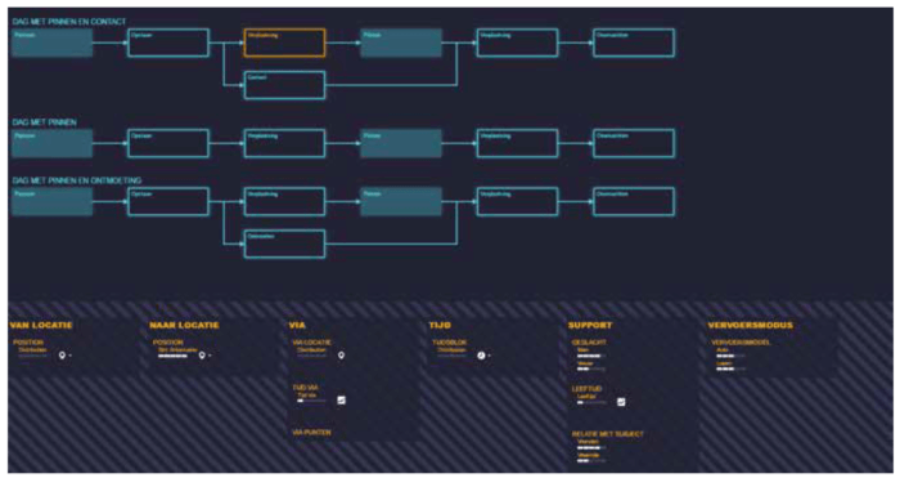
Elke scene is opgebouwd uit componenten voor subject, tijdsperiode, locatie(s), middelen en (menselijke) ondersteuning. Vervolgens zijn aan al deze componenten weer attributen gehangen voor onderscheidende eigenschappen. Daarmee wordt bijvoorbeeld van een tijdsperiode het dagdeel vastgelegd. Bij locatie zijn de karakteristieken vastgelegd in termen van afstand tot een stad, openbaar vervoer, water, bos. Bij support (een persoon die de voortvluchtige helpt) gaat het om geslacht en leeftijd, maar ook om de relatie die hij/zij heeft met de voortvluchtige. Gaat het hier om een bekende? Een bekende van een bekende? Of een volslagen vreemdeling?
Belangrijk om op te merken is dat bij het maken van de database alleen de afgeleide attributen opgeslagen worden. Hierdoor wordt geabstraheerd van de specifieke individuele casus en bevat de database geen informatie over exacte locaties of personen, maar alleen de karakteristieken en eigenschappen hiervan. Voor locaties kun je denken aan de afstand tot verschillende soorten point-of-interest, zoals restaurants, openbaar vervoer voorzieningen en stadscentra. Voor personen kun je denken aan geslacht, leeftijd, en relatie tot het subject. Op deze wijze kun je ook voor een nieuwe casus bepalen wat de meest waarschijnlijke invulling zal zijn, want als de eerste verplaatsing altijd wordt gedaan door de echtgenoot van de voortvluchtige, dan zal dat bij een nieuwe casus waarschijnlijk ook wel zo zijn. Zie ook figuur 1.
Redeneren Dit is de kern van het redeneerproces van QUIN, namelijk het uitrekenen hoeveel een huidige casus lijkt op historische zaken uit de database. De uitkomst van deze vergelijking is een getal, scenario similarity genaamd.
Om de scenario similarity van een huidige casus met een historische casus te bepalen wordt eerst gekeken of het bewijs kan passen in het corresponderende scenario template. Vervolgens wordt voor alle attributen in het bewijs de attribute similarity bepaald, waarvan het product wordt genomen.
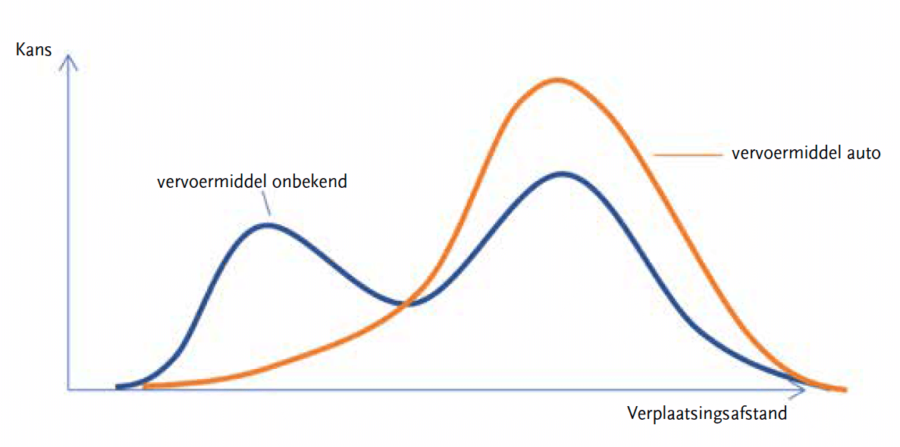
De hoogte van attribute similarity geeft aan hoeveel attribuut-waarden op elkaar lijken, bijvoorbeeld de leeftijden 38 (uit het bewijs) en 51 (uit historische data). De similarity schaal van een attribuut kan handmatig gedefinieerd worden, bijvoorbeeld hoeveel lijkt een broer op een neef? Voor continue waarden kan dit ook automatisch worden bepaald uit de historische data. Hierbij wordt er eerst de Silverman’s Bandwidth (Silverman, 1986) bepaald op basis van alle waarden van de attributen. Hoewel deze niet de meest nauwkeurige Kernel Density Estimation (KDE) oplevert, is deze wel zeer efficiënt te berekenen bij grote hoeveelheden data. De Silverman’s Bandwidth schrijft ook het gebruik van een normaalverdeling als basisfunctie voor de KDE voor. En met behulp van deze basisfunctie, de bandwidth, en alle attribuutwaarden kan dan een KDE gemaakt worden. De similarity is vervolgens uit te rekenen door de gemaakte verdeling te evalueren op de waarde van het attribuut uit het bewijs.
Als het verkregen bewijs op meerdere scenariotemplates past kunnen we met de scenario-similarity een uitspraak doen. Hierbij wordt gecorrigeerd voor het aantal attributen, omdat niet elk scenariotemplate evenveel attributen bevat.
Wanneer bepaald is wat de similarity is tussen de huidige casus en elke historische zaak, kan het systeem uitspraken doen over de verwachte waarden van onbekende informatie voor de huidige casus. Hiertoe wordt een posterior KDE opgesteld, door de verdeling van alle mogelijke attribuutwaarden te bepalen uit de historische zaken gewogen met de scenario similarity. Een voorbeeld hiervan is te zien in figuur 2.
Een analist heeft de mogelijkheid om bewijs (scenes, attribuutwaarden en (tijds)relaties) in te voeren in QUIN. Vervolgens heeft hij de mogelijkheid om de resultaten van QUIN-redeneringen te inspecteren. Hieronder bespreken we enkele visualisaties. Daarna bespreken we een voorbeeld van een werkwijze.
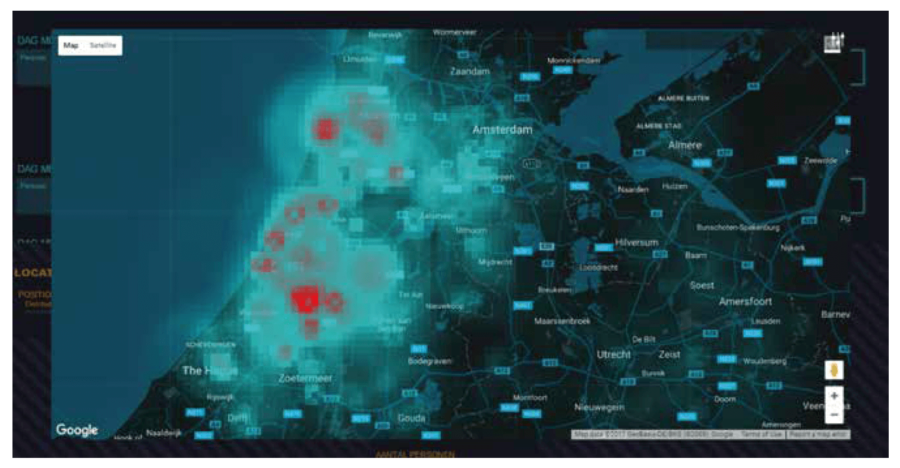
De scenario view (figuur 1) geeft een overzicht van mogelijke scenario’s en verwachte invullingen daarvan. Het meest waarschijnlijke scenario template wordt bovenaan getoond en toont de scenes met een korte beschrijving ervan. Wanneer een scene wordt geïnspecteerd is er een overzicht te zien van de componenten en attributen in die scene. Wanneer de waarde van een attribuut rechtstreeks uit het bewijs volgt is de waarde van het bewijs te zien. Als dat niet het geval is, is de verdeling van attribuutwaarden (de posterior KDE) te zien die uitgerekend is met behulp van de scenario similarities. Er zijn verschillende visualisaties voor de verwachte waarde van een attribuut, afhankelijk van het type attribuut. Voor een continue attribuut wordt een distributie plot gemaakt en voor een locatie wordt een kaart met een extra gekleurde laag getoond (figuur 3).
Door middel van de TRY-functie kan een analist hypotheses toetsen om soft evidence of aannames in te voeren, en die eenvoudig weer ongedaan maken. Hiermee kan ook de meerwaarde van (nog) onbekende informatie inzichtelijk gemaakt worden en kunnen ook hypotheses van bijvoorbeeld een profiler gebruikt worden om de voorspellingen aan te scherpen.
Deze visualisaties worden door de analist gebruikt als ondersteuning van de analyses en conclusies. Het is geen data-analyse die bewijs levert, maar het versterkt de argumentatie van een analist. Binnen het opsporingsteam van Hunted (figuur 4) is QUIN ingezet om te voorspellen waar de voorvluchtige zich schuil houdt: slaapt hij in het wild in de bossen, of logeert hij bij een vriend? Is hij bij een waarneming op doorreis of maakte hij een ommetje? Waar naartoe is hij op weg? En hoe lang gaat hij daar blijven? De analyses met QUIN bepalen mede hoe de opsporingscapaciteit wordt ingezet.
Voor het opsporingsteam van Hunted zat een belangrijke kracht van QUIN in het samenbrengen van gedragspatronen uit historische zaken met geografische analyse. Dit type analyse leent zich ook voor de toepassing van voortvluchtigen. Een dergelijke combinatie kan echter ook gemaakt worden tussen gedragspatronen en sociale relaties van betrokkenen, wat wellicht bij georganiseerde misdaad meer van belang is.
QUIN is een ondersteuningstool, en geen vervanger van een analist of rechercheur. De grootste meerwaarde valt te behalen als de uitkomsten goed kunnen worden geduid: Waar komt deze voorspelling vandaan (welke casussen hebben de grootste similarity)? En klopt dat? Ook het maken van hypotheses, het bepalen van soft evidence en het beoordelen van de betrouwbaarheid van informatie is iets dat juist de mens heel goed kan, en dat moet een dergelijke tool faciliteren, niet proberen te vervangen.

De gepresenteerde methode van QUIN laat zien hoe historisch gedrag in scenario’s vastgelegd kan worden, waardoor je nieuwe situaties kunt vergelijken met historische zaken. Het gaat om duiden (wat is er aan de hand?) en voorspellingen doen over wat je nog niet weet (hypotheses stellen). Op deze manier kan QUIN ingezet worden als instrument om te bepalen waarop je je opsporingsmiddelen het beste kunt richten. De aanpak via similarity en Kernel Density Estimators is generieker toepasbaar dan in alleen opsporingsonderzoeken of scenario-analyse.
Smit, S., Van der Vecht, B., Van Wermeskerken, F., & Streefkerk, J.W. (2016). QUIN: Providing Integrated Analysis Support to Crime Investigators. In Proceedings of Intelligence and Security Informatics Conference (EISIC), pp. 120–123. IEEE.
Cornish, D.B. (1994). The procedural analysis of offending and its relevance for situational prevention. Crime prevention studies, 3, 151–196.
De Kock, P.A.M.G. (2014). Anticipating criminal behaviour: Using the narrative in crime-related data. Tilburg University
Silverman, B.W. (1986). Density estimation for statistics and data analysis. CRC press.
STAtOR 2017 nr. 4 pagina 26-30
Bob van der Vecht studeerde kunstmatige intelligentie aan de Rijksuniversiteit Groningen en is hierin in 2oo9 gepromoveerd aan de Universiteit Utrecht. Hij werkt sindsdien als onderzoeker bij TNO op het gebied van operations research.
E-mail: bob.vandervecht@tno.nl
Freek van Wermeskerken studeerde wiskunde aan de Vrije Universiteit en behaalde zijn master in 2015 op het gebied van modelleren en optimalisatie. Na zijn afstuderen werkt hij bij TNO aan soortgelijke vraagstukken.
E-mail: freek.vanwermeskerken@tno.nl
Selmar Smit is aan de Vrije Universiteit gepromoveerd op het onderwerp machine learning, en sindsdien werkzaam als onderzoeker en adviseur op het gebied van artificial intelligence bij TNO.
E-mail: selmar.smit@tno.nl





